# O que são redes neurais
Redes neurais são um conjunto de algoritmos que se assemelham ao cérebro humano e são projetados para reconhecer padrões. Eles interpretam os dados sensoriais através de uma percepção da máquina, rotulando ou agrupando dados brutos. Eles podem reconhecer padrões numéricos, contidos em vetores, nos quais todos os dados do mundo real (imagens, som, texto ou série temporal) devem ser traduzidos. As redes neurais artificiais são compostas por um grande número de elementos de processamento altamente interconectados (neurônio) trabalhando juntos para resolver um problema
Um histórico resumido sobre Redes Neurais Artificiais deve começar por três das mais importantes publicações iniciais, desenvolvidas por: McCulloch e Pitts (1943), Hebb (1949), e Rosemblatt (1958). Estas publicações introduziram o primeiro modelo de redes neurais simulando “máquinas”, o modelo básico de rede de auto-organização, e o modelo Perceptron de aprendizado supervisionado, respectivamente.
# Características Gerais das Redes Neurais
Uma rede neural artificial é composta por várias unidades de processamento, cujo funcionamento é bastante simples. Essas unidades, geralmente são conectadas por canais de comunicação que estão associados a determinado peso. As unidades fazem operações apenas sobre seus dados locais, que são entradas recebidas pelas suas conexões. O comportamento inteligente de uma Rede Neural Artificial vem das interações entre as unidades de processamento da rede.
A operação de uma unidade de processamento, proposta por McCullock e Pitts em 1943, pode ser resumida da seguinte maneira:
- Sinais são apresentados à entrada;
- Cada sinal é multiplicado por um número, ou peso, que indica a sua influência na saída da unidade;
- É feita a soma ponderada dos sinais que produz um nível de atividade;
- Se este nível de atividade exceder um certo limite (threshold) a unidade produz uma determinada resposta de saída.
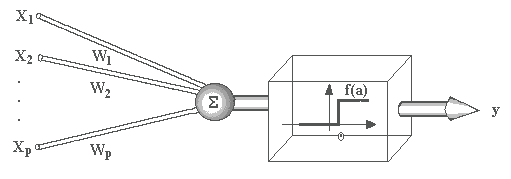
Suponha que tenhamos p sinais de entrada X1, X2, ..., Xp e pesos w1, w2, ..., wp e limitador t; com sinais assumindo valores booleanos (0 ou 1) e pesos valores reais.
Neste modelo, o nível de atividade a é dado por:
a = w1X1 + w2X2 + ... + wpXp
A saída y é dada po
y = 1, se a >= t ou
y = 0, se a < t.
A maioria dos modelos de redes neurais possui alguma regra de treinamento, onde os pesos de suas conexões são ajustados de acordo com os padrões apresentados. Em outras palavras, elas aprendem através de exemplos.
Arquiteturas neurais são tipicamente organizadas em camadas, com unidades que podem estar conectadas às unidades da camada posterior.
# Backpropagation (ou retropropagação)
No aprendizado de máquina, a retropropagação é um algoritmo amplamente utilizado no treinamento de redes neurais feedforward para aprendizado supervisionado.
Ao ajustar uma rede neural, a retropropagação calcula o gradiente da função de custo com relação aos pesos da rede para um único exemplo de entrada e saída e o faz com eficiência, diferentemente de um cálculo direto ingênuo do gradiente com relação a cada peso individualmente. Essa eficiência viabiliza o uso de métodos gradientes para o treinamento de redes multicamadas, atualizando pesos para minimizar perdas; descida de gradiente, ou variantes como descida de gradiente estocástica, são comumente usadas. O algoritmo de retropropagação funciona calculando o gradiente da função de perda com relação a cada peso pela regra da cadeia, calculando o gradiente uma camada por vez, repetindo a última camada para evitar cálculos redundantes de termos intermediários na regra da cadeia; este é um exemplo de programação dinâmica.
# Recurrent Neural Networks
Redes recorrentes são um tipo de rede neural artificial projetada para reconhecer padrões em seqüências de dados, como texto, genomas, caligrafia, palavra falada ou dados numéricos de séries temporais emanados de sensores, mercados de ações e agências governamentais. Esses algoritmos levam em consideração o tempo e a sequência, e possuem uma dimensão temporal. Pesquisas mostram que eles são um dos tipos mais poderosos e úteis de redes neurais. RNNs são aplicáveis mesmo a imagens, que podem ser decompostas em uma série de "remendos" (patches) e tratadas como uma sequência.
Para o melhor entendimento sobre as RNN's, é bom antes falar sobre as redes feedfoward. Ambas as redes recebem o nome da forma como canalizam informações através de uma série de operações matemáticas realizadas nos nós da rede. As redes feedforward alimentam informações diretamente (nunca tocando em um determinado nó duas vezes), enquanto as redes recorrentes percorrem através de um loop.

Ou seja, uma rede feedforward não tem noção de ordem no tempo, e a única entrada que considera é o exemplo atual a que foi exposta. As redes feedforward são amnésicas em relação ao seu passado recente; elas lembram nostalgicamente apenas os momentos formativos do treinamento.
As redes recorrentes, por outro lado, tomam como entrada não apenas o exemplo de entrada atual que veem, mas também o que perceberam anteriormente no tempo. A decisão de uma rede recorrente alcançada na etapa de tempo t-1 afeta a decisão que alcançará um momento mais tarde na etapa de tempo t. Assim, as redes recorrentes têm duas fontes de entrada, o presente e o passado recente, que se combinam para determinar como respondem a novos dados, da mesma forma que fazemos na vida.
# Os problemas das RNN
Apesar de tudo, as redes neurais recorrentes possuem alguns problemas, dentre os quais podemos destacar:
- Dissipação e explosão de gradiante (Gradient vanishing and exploding).
- Treinar um RNN é uma tarefa muito difícil.
- Ele não pode processar seqüências muito longas se estiver usando tanh (opens new window) ou relu (opens new window) como uma função de ativação.
# Redes LSTM
As redes Long Short-Term Memory (LSTM) são uma versão modificada de redes neurais recorrentes, que facilitam a lembrança de dados anteriores na memória. O problema do gradiente de fuga (vanishing gradient) das RNN's é resolvido aqui. O LSTM é adequado para classificar, processar e prever séries temporais, visto que os LSTMs são projetados para evitar o problema de dependência de longo prazo. Ele treina o modelo usando back-propagation (ou retropropagação).
Em uma rede LSTM, três 'portões' (gates) estão presentes:

Portão de entrada: descobre qual valor da entrada deve ser usado para modificar a memória. A função sigmóide decide quais valores deixar passar entre 0 e 1. e a função tanh atribui peso aos valores passados, decidindo seu nível de importância variando de -1 a 1.
Portão de esquecimento: descobre quais detalhes devem ser descartados do bloco. É decidido pela função sigmóide. O portão olha o estado anterior (ht-1) e conteúdo de entrada (Xt) e gera um número entre 0 (omita isso) e 1 (mantenha isso) para cada número no estado da célula Ct-1.
Portão de saída: a entrada e a memória do bloco são usadas para decidir a saída. A função sigmóide decide quais valores deixar passar, entre 0 e 1, e a função tanh dá peso aos valores passados, decidindo seu nível de importância, variando de -1 a 1 e multiplicado pela saída da sigmóide.

# Referências
Características das redes neurais (opens new window)
Redes Neurais Recorrentes (opens new window)
A Beginner's Guide to LSTMs and Recurrent Neural Networks (opens new window)
MACHINE LEARNING DE SÉRIES TEMPORAIS – LSTM (opens new window)